
Un libro de códigos es un documento que contiene información detallada de una fuente de datos, tales como nombres de variable, etiquetas de variable, etiquetas de valores o valores perdidos. Un libro de códigos bien documentado permite conocer el contenido, estructura y diseño de un estudio, lo cual facilita vincular las preguntas del cuestionario con cada una de las variables en la base de datos.
Cuando nos encontramos frente a extensas fuentes de datos, el navegar por cada una de sus partes se puede hacer confuso y complicado. Para abordar este problema, necesitamos una “hoja de ruta” de nuestros datos, es decir “dónde está qué” y “cómo podemos encontrarlo”. En este sentido, es habitual que dentro de la documentación de las fuentes de datos venga acompañada de esta “hoja de ruta” llamada libro de códigos.
En ocasiones, nuestros proyectos de investigación producen sus propios datos que tienen como resultado una base de datos, es decir, una matriz de información con filas y columnas que representan observaciones (filas) y atributos (columnas). Así, para una adecuada comprensión y descripción de estos datos, necesitamos un libro de códigos que oriente en la persona que se disponga “navegar” en dicha información.
Como se mencionó anteriormente, un libro de códigos ofrece una descripción precisa de la información dentro de una base de datos. La Figura 1 presenta un ejemplo del International Social Survey Programme del año 2009. Aquí se puede observar lo que comúnmente se encuentra en un libro de códigos, conteniendo el nombre de las variables del estudio, su nivel de medición, valores, etiquetas de valores y valores perdidos. En ocasiones, se incluyen estadísticos descriptivos y de tendencia central, según corresponda al tipo de variable en cuestión; y en el mejor de los casos, visualización de información a través de cuadros o figuras.
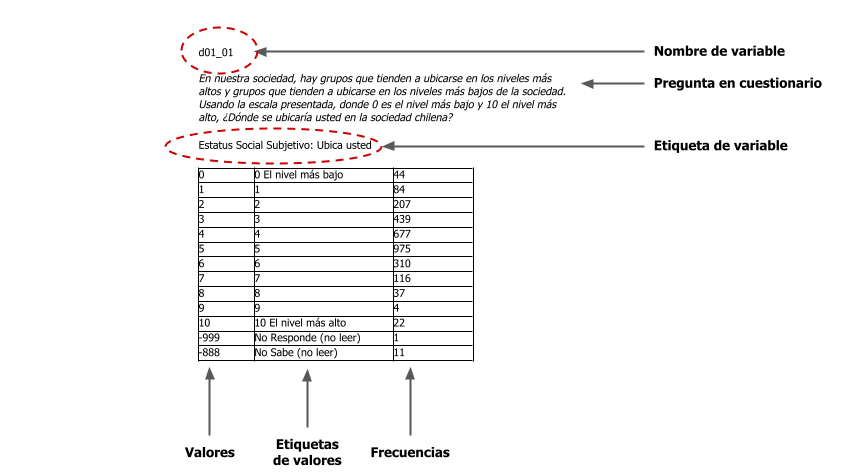
Figura: Libro de códigos para variable “V44” en base de datos del módulo Social Inequality 2009 de ISSP.
Algunas sugerencias básicas de lo que puede incluir libro de códigos son las siguientes:
- Nombre de variable: El nombre o numeración asignada a cada variable en la base de datos. En algunas ocasiones se utilizan abreviaciones mnemotécnicas (TOPBOTOM) o patrones alfanuméricos (d01_01). Para los datos provenientes de encuestas se sugiere emplear los números de las preguntas (P01, P02).
- Etiqueta de variable: Una descripción breve que permite identificar la variable. Si es posible, se sugiere utilizar un fragmento del fraseo de la pregunta en el cuestionario.
- Valores: Los valores reales de la variable (p.ej: 1, 2, 3, 4, 5)
- Etiquetas de valores: El texto asignado a cada uno de los valores de variable (Totalmente en desacuerdo, En desacuerdo, Ni de acuerdo ni en desacuerdo, De acuerdo, Totalmente de acuerdo)
- Valores perdidos: Si aplica, son los valores y etiquetas de valores para los datos perdidos. La correcta descripción de estos datos evita problemas en los análisis, por lo cual deben estar correctamente descritos (ver sección de Bases de datos, Codificación de las respuesta)
Generar un libro de códigos
Teniendo en cuenta lo anterior, existen distintas maneras de producir un libro de códigos. Por un lado podemos generarlo manualmente, sistematizando y ordenando la información en un documento. Sin embargo esto puede ser tedioso cuando se trata de fuentes de datos de gran tamaño. Por esta razón, existe la posibilidad de automatizar la creación de un documento empleando un software estadístico, tales como SPSS, Stata o R.
Cada uno de los software mencionados tiene distintas funciones que nos permiten obtener la información necesaria para un libro de códigos.
- Por un lado, en SPSS tenemos el comando
CODEBOOK.Por otro lado, en Stata existe el comandocodebook. En ambos casos, el software entrega una salida con información para cada variable: nombre, etiqueta, etiquetas de valores y frecuencias. - En R no existe una única forma de obtener un libro de códigos. Sin embargo, la función
view_df()de la libreríasjPlotnos ofrece una salida de buena calidad. Otra alternativa es emplear la funciónfrq()de la librería sjmisc, la cual entrega los nombres de variable, etiqueta y etiquetas de valores junto a las frecuencias, media y desviación estándar. - Es importante mencionar que para las tres opciones, sus variables deben estar correctamente etiquetadas.
| Software | Función | Ejemplo |
|---|---|---|
| SPSS |
CODEBOOK
|
Codebook en SPSS |
| STATA |
codebook
|
Codebook en STATA |
| R |
view_df()
|
Codebook en R |
frq()
|
¿Quieres comentar o tienes alguna duda?
Puedes dejar tus comentarios y dudas sobre el visualizador en nuestro foro. De todas formas puedes contactarnos